AI and Data in Horse Racing Betting: The 2026 UK Punter’s Reality Check
html
Contents
AI hype meets a 350-year-old market
Every few months I see a new product advertised that promises to use artificial intelligence to beat the horse racing market. The pitch is always the same: decades of data, sophisticated algorithms, neural networks trained on millions of races, and a subscription that costs less than a decent meal. The implication is that human form analysis is obsolete and the machines have cracked the code. Having tested several of these products and built my own modest models over the years, I can say with confidence that the reality is more nuanced, more interesting, and far less profitable than the marketing suggests.
Online betting on UK racing saw a 17% year-on-year growth in 2026, partly attributed to the rising influence of data-driven and AI-assisted platforms. The global market for AI in sports betting is projected to grow from $10.8 billion in 2026 to over $60 billion by 2034. Those numbers describe a real trend, but they encompass everything from sophisticated in-house bookmaker models to retail tipster services that apply the label “AI” to a basic database query. Understanding what AI actually does in racing, and where its limitations bite, is essential for any punter tempted by the hype.
The data sources behind modern models
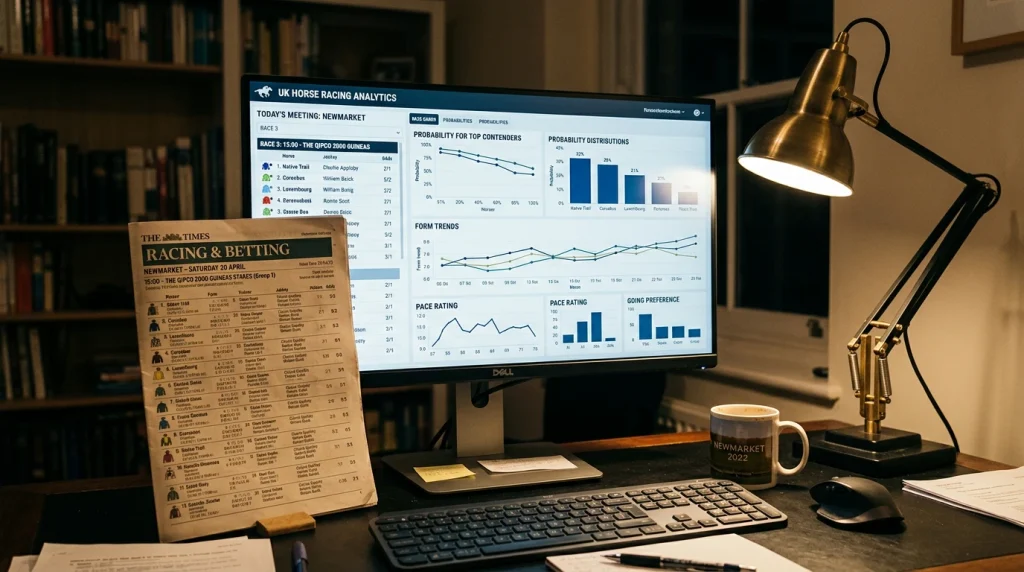
A racing prediction model is only as good as the data it consumes, and the quality and breadth of available data determine the ceiling of what any model can achieve. The core dataset for UK racing includes historical results, official ratings, race distances, going conditions, draw positions, jockey and trainer records, weight carried, finishing distances, and starting prices. This data is publicly available through services like Racing Post, Timeform, and the BHA’s own results database.
More advanced models incorporate supplementary data layers: sectional timing data where available, GPS tracking information from races equipped with transponder technology, veterinary records, breeding databases, weather forecasts, and market price movements. Each additional data source adds potential predictive power but also adds noise – irrelevant correlations that the model may overfit to, particularly when the dataset is small relative to the number of variables.
The UK’s data infrastructure is improving but remains less comprehensive than some international jurisdictions. Sectional timing, which provides split times for defined portions of a race, is available at an increasing number of courses but is not yet universal. This means that pace analysis – one of the most powerful predictive angles in racing – relies on partial data supplemented by human observation for many UK meetings.
What kinds of models actually work
The models that produce genuine edges in UK horse racing tend to be narrow rather than broad. A model that specialises in Flat handicaps at specific courses, trained on data that captures the unique characteristics of those courses – draw bias, pace dynamics, going effects – will typically outperform a general-purpose model that attempts to price every race at every course. Specialisation allows the model to learn the patterns that matter within a constrained domain, rather than drowning in the noise of a dataset that spans wildly different race types.
Statistical approaches that work in practice include logistic regression for estimating win probabilities, gradient-boosted decision trees for handling non-linear relationships between variables, and ensemble methods that combine multiple weak predictors into a stronger overall estimate. Deep learning – the branch of AI that gets the most breathless coverage – has not demonstrably outperformed simpler methods in UK horse racing, partly because the datasets are too small for neural networks to learn the complex patterns that justify their architectural complexity.
The most successful model-based punters I know use their models as a first filter, not a final verdict. The model generates probability estimates for every runner, and the human then reviews the model’s output against the racecard, looking for factors the model cannot capture: late jockey changes, paddock appearance, the significance of a trainer switching a horse between races at different meetings. The model handles the data-intensive computation; the human handles the judgment calls.
The growing role of sectional data
Sectional timing is the data source with the greatest potential to transform UK racing analysis. Traditional race times – the overall time from start to finish – are blunt instruments that tell you how fast the race was but not how it was run. Sectional times break the race into segments and reveal where each horse gained or lost ground, how quickly the pace was set, and whether a horse was finishing strongly or tiring in the closing stages.
In the UK, TurfTracker and Total Performance Data are the primary providers of sectional information, and coverage is expanding as more courses install the necessary timing infrastructure. At courses where sectionals are available, the data reveals insights invisible to the naked eye: a horse that finished fifth might have run the fastest final two furlongs in the race, suggesting it was denied a clear run and is better than the bare form suggests.
For the model-building punter, sectional data is a competitive advantage that is still in its early adoption phase. The majority of UK punters and a surprising number of professional tipsters do not yet incorporate sectionals into their analysis, which means the market has not fully priced in the information they contain. That window of opportunity will narrow as adoption increases, but in 2026 it remains one of the few genuine informational edges available to the data-literate punter.
Where human judgement still beats the model
Models excel at processing large volumes of historical data and identifying patterns that repeat with statistical significance. What they cannot do is respond to information that has no historical precedent, or assess variables that are inherently qualitative rather than quantitative.
Paddock assessment is the most obvious example. A horse that appears tense, sweaty, or uncomfortable in the parade ring is telling you something about its mental state that no historical database can capture. Experienced racegoers who can read body language – the way a horse walks, the set of its ears, the quality of its coat – possess information that the model has no access to, and that information can be the difference between a confident selection and a costly mistake.
Tactical scenarios within a race are another area where human judgement dominates. A model can estimate how a race is likely to be run based on the running styles of the declared runners, but it cannot predict that a jockey will adopt an unconventional tactic – taking a hold-up horse to the front, for example, or dropping a front-runner in behind for the first time. These tactical decisions are made by humans in real time, often based on information observed during the preliminary canter or the early strides of the race itself.
The third area where humans retain an edge is in understanding the motivations of connections. A trainer who enters a horse in a weak race at a minor meeting may be doing so to build confidence after a setback, to find easier opposition, or to exploit a specific set of conditions. The model sees the entry as a data point; the experienced punter reads it as a signal of intent. That distinction matters, and it is why the most successful racing punters I know combine data-driven analysis with deep knowledge of the sport’s human dynamics.